사내에서 Querydsl에 대해 Tech Talk 진행할 기회가 생겨 준비한 내용을 기록합니다
Querydsl
- 타입에 안전한 방식으로 HQL 쿼리를 실행하기 위한 목적으로 만들어짐
- 타입에 안전하도록 도메인 모델을 변경하면 소프트웨어 개발에서 큰 이득을 얻게 됨
- 도메인 변경이 직접적으로 쿼리에 반영됨
- 쿼리 작성 과정에서 코드 자동완성 기능을 사용함으로써 쿼리를 더 빠르고 안전하게 만들 수 있게 됨
- JPA, JDO, JDBC, Lucene, Hibernate Search, MongoDB, Collections 그리고 RDFBean을 지원
사용하기
- 도메인 타입 작성(ex: Customer)
- Querydsl에 의해 자동으로 QCustomer라는 쿼리타입 생성
- (JPA의 경우) JPAQuery 인스턴스로 쿼리 작성
- 결과 처리(다중 컬럼, Setter기반, 필드기반, 생성자기반, 어노테이션기반 등)

- Qcustomer 쿼리타입은 자동생성된다.
- QCustomer는 기본 인스턴스 변수를 갖고 있으며, 정적 필드로 접근할 수 있다. QCustomer customer = QCustomer.customer;
- 다음처럼 Customer 변수를 직접 정의할 수도 있다. QCustomer customer = new QCustomer("myCustomer");
JPA에서의 기존 사례 - 고객의 이름과 나이로 조회
Method Naming 방식

간단한 쿼리의 경우 정말 편하고 개발속도가 빠르다. 단점은 복잡할수록 길어지며 읽기 힘들다.
JPQL (Java Persistence Query Language)

https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.query-methods
- JPA는 JPQL을 생성하고 JPQL은 SQL을 생성한다.
- JPQL은 엔티티를 대상으로 쿼리한다.
- 객체지향적으로 쿼리할 수 있다, 옵션으로 native query도 가능하다,
- 문자열기반 쿼리의 단점을 그대로 볼수 있다. 런타임시점에서 오류를 발견 가능하다. (IDE의 발전으로 IDE에서 발견할 수도 있다)
- Criteria(크리테리아 – 객체지향 쿼리빌더)가 있지만 코드가 장황해지고 복잡하며 직관적으로 이해하기 힘들다.
Querydsl에서는?
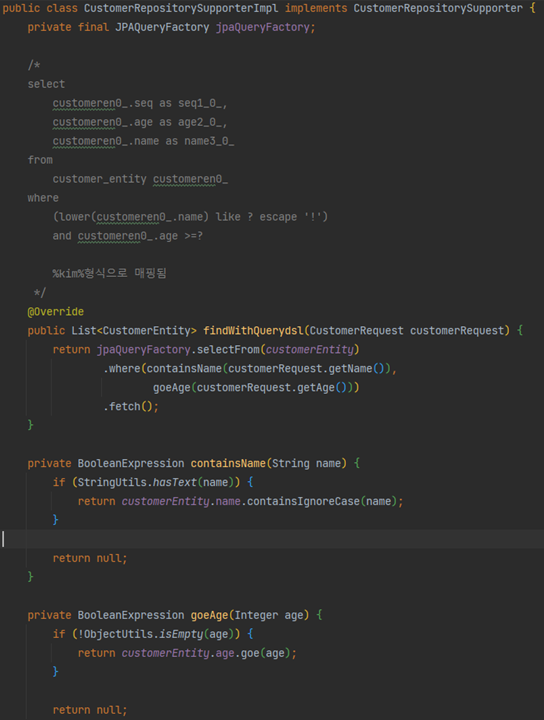
JPAQuery 인스턴스를 이용하여 쿼리작성하며 Expressions를 이용하여 동적인 표현식을 생성 할 수 있다.
일반용법
- from: 쿼리 소스를 추가한다.
- innerJoin, join, leftJoin, fullJoin, on: 조인 부분을 추가한다. 조인 메서드에서 첫 번째 인자는 조인 소스이고, 두 번재 인자는 대상(별칭)이다.
- where: 쿼리 필터를 추가한다. 가변인자나 and/or 메서드를 이용해서 필터를 추가한다.
- groupBy: 가변인자 형식의 인자를 기준으로 그룹을 추가한다.
- having: Predicate 표현식을 이용해서 "group by" 그룹핑의 필터를 추가한다.
- orderBy: 정렬 표현식을 이용해서 정렬 순서를 지정한다. 숫자나 문자열에 대해서는 asc()나 desc()를 사용하고, OrderSpecifier에 접근하기 위해 다른 비교 표현식을 사용한다.
- limit, offset, restrict: 결과의 페이징을 설정한다. limit은 최대 결과 개수, offset은 결과의 시작 행, restrict는 limit과 offset을 함께 정의한다.
검색조건

.and(), .or() 메서드 체인으로 연결할 수 있다.(혹은 and의 경우 , 가능)
조인

- Join(조인 대상, 쿼리 타입(별칭)) 패턴, Querydsl은 JPQL의 이너 조인, 조인, 레프트 조인, 풀조인을 지원한다 조인 역시 타입에 안전
- 두 엔티티간의 연관관계가 정의되어 있지 않아도 조인 가능(Hibernate 5.x 이상)
조인 – 묵시적(암시적, implicit) 조인 주의
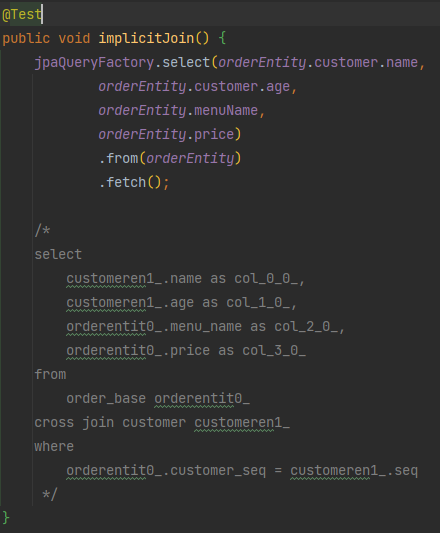
- JPQL에서는 select절에서 의존성을 가지는 다른 엔티티 객체를 조회 하려할 때 JPA가 알아서 PK와 FK를 가지고 해당 테이블과 조인을 해준다. 하지만 cross join이 발생 할 수 있으므로 명시적 조인이 권장된다.
- 묵시적 조인은 ANSI-89에서 ANSI-92 넘어가면서 deprecated되었다.
조인 – fetch join
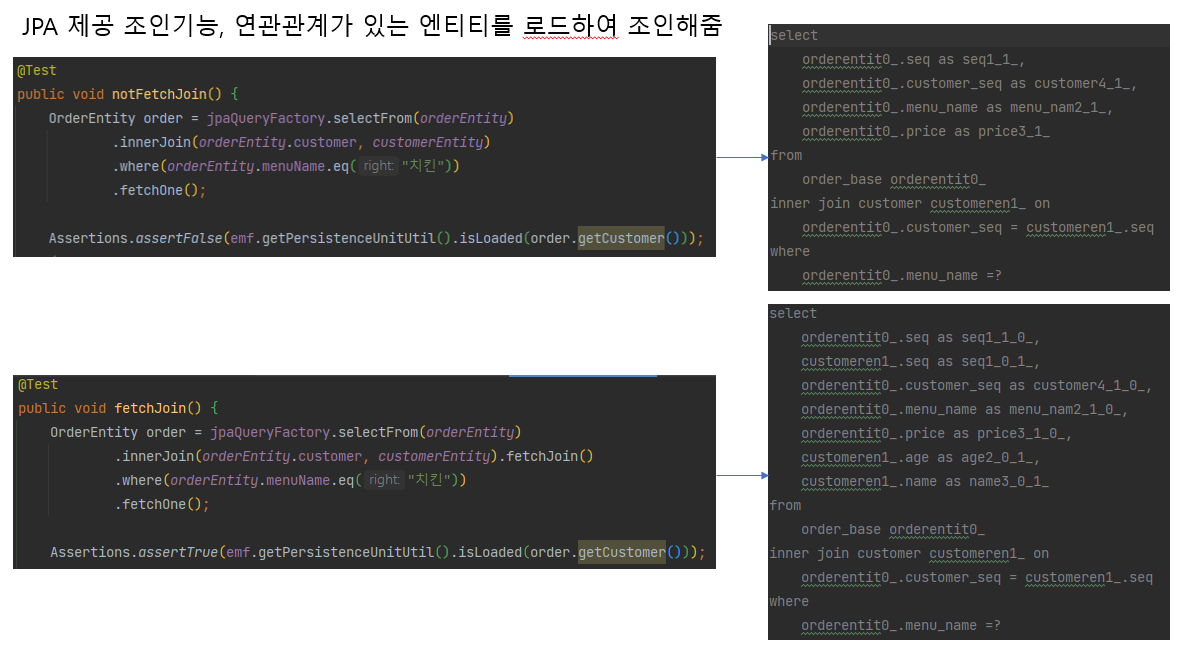
FetchType.EAGER는 미리 로드된 상태
실제로 쿼리수행시 FetchJoin테스트의 쿼리문은 customerEntity의 내용도 포함한다.
fetchJoin 미사용시 OrderEntity에는 CustomerEntity는 로드되지 않고, 결과에서도 CustomerEntity의 컬럼은 포함되지 않았다.
그룹핑

JPQL의 모든 집합 함수를 제공
- 합산: orderEntity.price.sum()
- 평균: orderEntity.price.avg()
- 최소: orderEntity.price.min()
- 최대: orderEntity.price.max()
- 카운트: orderEntity.price.count()
groupBy()로 그룹핑 가능, 그룹결과제한은 having() 체인으로 가능하다
결과조회

쿼리 작성 후 결과 조회는 다음의 메서드로 제공된다
- fetch: List<entity> 조회
- fetchOne: 단건 조회(복수결과시 에러)
- fetchFirst: limit(1).fetchOne()과 동일
- fetchCount: 결과 count 반환(count()함수 적용)
- fetchResults: 페이징정보를 포함하여 반환 count 쿼리도 동시 조회
결과처리
조회된 데이터를 커스터마이징하는 단계
- 다중 컬럼 방식(Tuple 타입 제공)
- Bean 방식 – (1) Setter
- Bean 방식 – (2) Field
- 생성자 방식 – (1) 생성자
- 생성자 방식 – (2) 어노테이션 방식 (@QueryProjection)
결과처리 - 다중 컬럼 방식
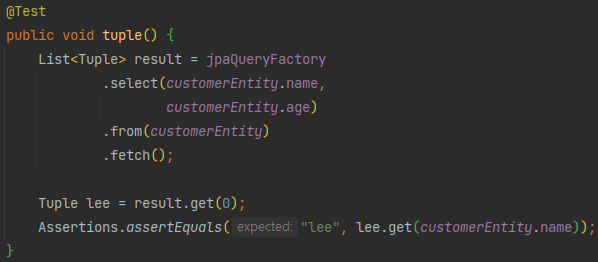
Tuple은 안전한 Map을 제공하고, 이를 통해 직접 Tuple 행 객체로부터 데이터에 접근 할 수 있다.
결과처리 - Bean 방식 - (1) Setter

Bean 프로젝션을 사용하여 Dto 객체를 생성할 수 있다
기본생성자가 열려 있어야 하고, 주입하려는 변수의 Setter 메서드가 존재해야 한다

결과처리 - Bean 방식 - (2) Field

필드에 직접 접근하여 생성하는 방식이다. Setter 메서드를 필요로 하지 않고, 리플렉션을 이용하므로 필드를 private로 지정해도 동작한다 대신 테스트 방식이 제한적이고 힘들다.
결과처리 - 생성자 방식 - (1) 생성자

- 결과에 맞는 생성자가 필요하므로 불필요한 생성자가 여럿 존재할 수 있고, 생성자와 바인딩할 값의 순서가 일치해야 한다
- IDE 자동완성기능을 이용할 수 없고, 실수가 발생할 수 있다.(값이 많아지면)
결과 처리 - 생성자 방식 - (2) 어노테이션

@QueryProjection 어노테이션을 생성자에 달면, 해당 생성자 기반으로 쿼리타입이 생성된다. 이를 이용해 IDE 자동완성을 이용하면서 생성자 방식의 결과 처리를 진행할 수 있다.
참고https://querydsl.com/static/querydsl/4.4.0/reference/html_single/https://github.com/querydsl/querydsl/tree/master/querydsl-collections/src/test/java/com/querydsl/collections
'Spring' 카테고리의 다른 글
| @EnableScheduling 설정하지 않았는데 Schedule 동작 시 (0) | 2024.01.17 |
|---|---|
| Thymeleaf - 표준 표현식 (0) | 2021.01.27 |
| SpringBoot Mysql Datasource 세팅 (0) | 2020.11.16 |
| Spring Cloud Gateway - API Gateway 맛보기 (5) | 2020.10.19 |
| Spring Security OAuth2 - Authorization endpoint (0) | 2020.10.07 |